Features of standalone (embedded like sqlite) and server versions of VelocityDB |
Standalone
Version
|
Server Version
|
|
Scalable (smart caching enables millions of database to be used
without running out of memory). From the smallest to the largest databases in
the world, VelocityDB can handle it nicely
|
|
|
|
High Performance (objects are created the same way transient
objects are and are made persistent efficiently when requested, persistence does
not change the object, just adds an object identifier)
|
|
|
|
Any serializeable object can be persisted
|
|
|
|
Compression (optional at page level, controlled by user for
each database location)
|
|
|
|
Encryption (optional at page level, controlled by user for each
database location)
|
|
|
|
Indexes (Declarative by using Index attribute in class definitions, index BTree's are maintained automatically by the system)
|
|
|
|
Database Replication with automatic switch to healthy replica
|
|
|
|
Copy all database files to a local directory (A very simple and easy way to backup your data)
|
|
|
|
Export & Import to/from JSON
|
|
|
|
Export & Import to/from CSV files (Each type of object gets its own csv file)
|
|
|
|
Optional automatic incremental contiguous backup of all data in a database location to a backup location
|
|
|
|
Full Database backup (API for copying all database files in a "federation" to a selected directory. Can also be done using the Database Manager) |
|
|
|
Variable page size (from a few bytes to GB’s depending on how
many objects and their sizes). Databases and pages do not contain any unused
bytes (unlike fixed size database pages), only space for allocated objects |
|
|
|
Auto recovery build in (no journal files required)
|
|
|
|
Cloud enabled, most simple, affordable and efficient cloud choice might be to use Microsoft Azure file storage. VelocityDBServer can also be used from within any cloud platform.
|
|
|
|
Transaction control, (Atomicity, Consistency, Isolation, Durability) is supported.
|
|
|
|
Choice of Pessimistic locking and Optimistic locking
|
|
|
|
Change event subscription and notification
| |
|
|
Page level locking
| |
|
|
In-Memory Only Option turns VelocityDB into a powerful In-Memory database. It can be used in combination with High Availability functionality replicating data between servers.
| |
|
|
Database level locking
|
|
|
|
Each persistent object has an object identifier, a 32 bit
Database number – a 16 bit Page number – a 16 bit Slot number, (stored as a
single 64 bit number)
|
|
|
|
[UseOidShort] attribute for references within a
Database. Use attribute for an entire class or for selected fields of a class.
|
|
|
|
Shared cache for all users (on server side)
|
|
|
|
Local cache for each client
|
|
|
|
Pure C#, no SQL and no unmanaged code
with a small set of easy to use API
|
|
|
|
Small footprint, the C# DLL is ~500 KB, the server is 11 KB |
|
|
|
Automatic use of efficient binary search lookups with LINQ query over a BTreeSet using CompareByField comparator. |
|
|
|
Scalable, compact and super-efficient BTreeSet<Key> and BTreeMap<Key>
collections are provided for keeping track of large sorted collections. Other
collections provided include: VelocityDbHashSet<T>, SortedSetAny<Key>,
SortedMap<Key, Value> and,
VelocityDbList<Key> |
|
|
|
Spatial
access methods, an RTree collection is provided inspired by a description on Wikipedia
with some enhancements. We have plans to add polygon API, let us know if you need it? |
|
|
|
A WeakReference<T> class is provided that avoids pinning of
large graphs of related objects. Objects are brought back on demand (we save the
object identifier in the WeakReference)
|
|
|
|
Persistent objects can be unpersisted which removes the object
from the persistent storage, and then again can be used as any transient object.
These can later be persisted again, possibly in a different database
|
|
|
|
Databases can be distributed to as many hosts as required
|
|
|
|
A popular database term these days is Sharding, the distributable nature of VelocityDB supports this. You define each partition by creating database locations (host+path) for a range of database id's.
You can reconfigure these locations whenever you need to. |
|
|
|
Linq, Use it with; Indexes, persistent collections, Databases or session (AllObjects<T>()) |
|
|
|
No Database catalog, only database locations
|
|
|
|
Automatic deadlock detection
|
|
|
|
Automated tracking of all update transactions and what they update
|
|
|
|
Using Windows Authentication when accessing server(s)
|
|
|
|
Placement class for selecting where to store persistent
objects. Each persistent class can also help decide about the placement by
overriding some base class API. Persistent placement can further be controlled
by the field attribute: [ObjectsPerPage(1)] which specifies how many objects are
allowed on the same page (in this case 1). |
|
|
|
Transient data members in persistent objects are supported by
tagging them [NonSerialized]
|
|
|
|
Auto Increment on a field, similar to feature in SQL, by tagging them [AutoIncrement]
|
|
|
|
Invalidate only cached pages updated by a different client (session) instead of all pages within a Database when a page or more has been updated by another client transaction
|
|
|
|
LINQPad Driver
|
|
|
|
Asp.Net Identity Driver (source code and sample web app provided)
|
|
|
|
GeoHash support (source code and sample app provided). Ported from a Java implementation.
|
|
|
A DatabaseManager for database administration and browsing of data objects
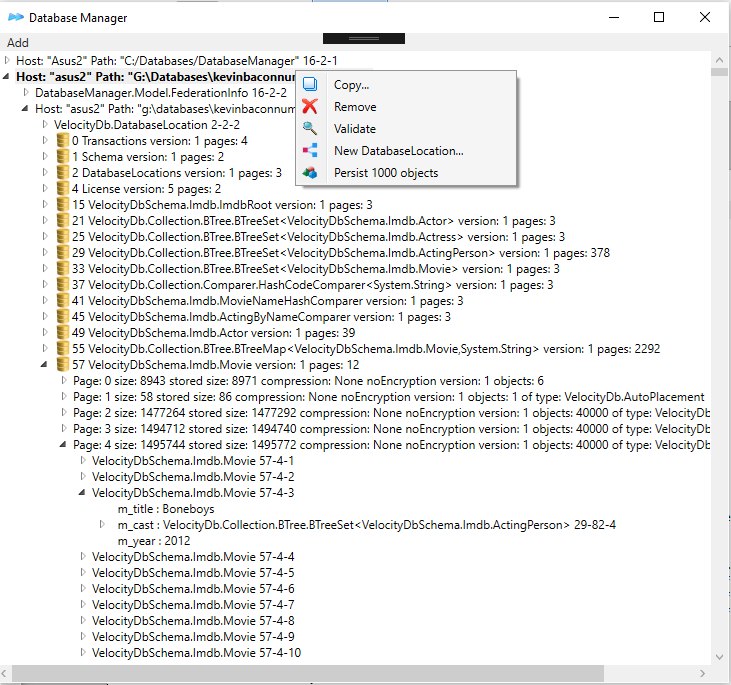 |
|
|